
Unsupervised Latent Tree Induction with Deep Inside-Outside Recursive Autoencoders (DIORA)
이 논문은 inside-outside를 사용하여 모든 binary (sub-)tree에 대한 score 및 representation을 계산하고, CYK로 max-scored tree를 찾는다. Constituent representation을 구할 수 있다는 것이 강점이다.
모델
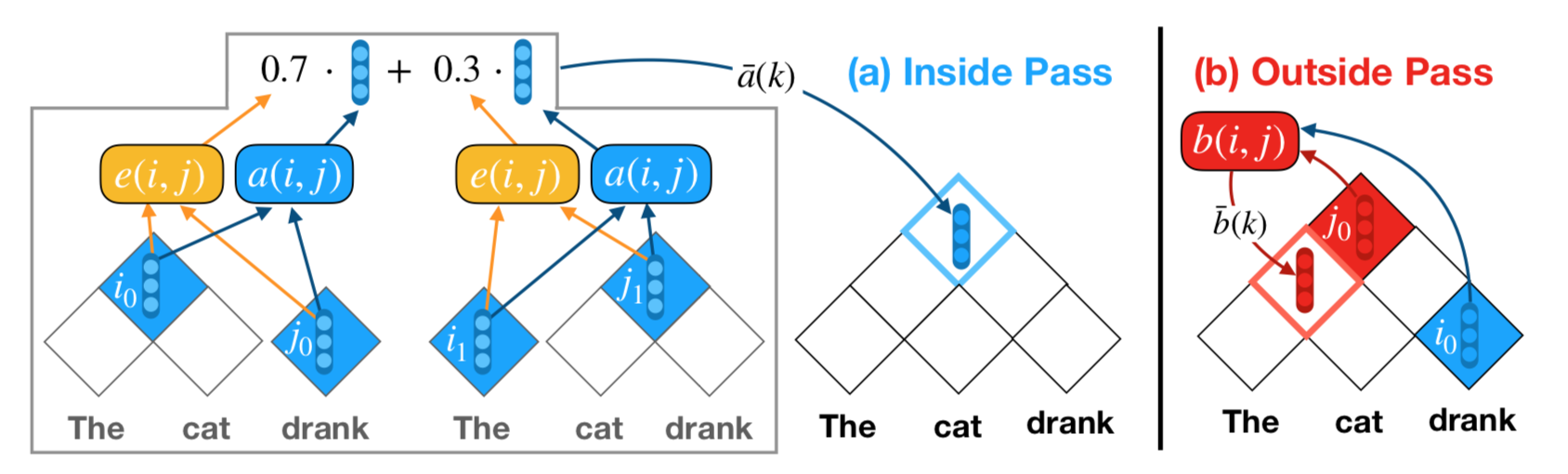
Inside Pass: Look only the inside subtrees
Bottom-up 방식으로, 두 child의 inside representation과 그들의 결합 확률로부터 parent의 inside representation을 만든다.
1) 두 constituent $i, j$ 에 대해서, composition vector $\bar{a}(i), \bar{a}(j)$, 그리고 final parse tree에 존재할 확률에 대한 점수 $\bar{e}(i), \bar{e}(j)$ 가 주어져 있다고 하자.
2) $i, j$ 에 대해서 composition score $a(i,j)$ 및 둘이 merge될 수 있는 확률을 나타내는 normalized compatibility score $e(i,j)$ 를 구한다. 논문은 composition function으로 TreeLSTM 또는 MLP를 사용하였다.
3) 이제 span $k$ 에 대해서, $k$ 를 fully cover할 수 있는 모든 $(i,j)$ pair를 고려하여 (즉 모든 가능한 children 쌍에 대해서) composition vector 및 parse tree에 존재할 점수를 계산한다.
Outside Pass: Look only the outside contexts
Top-down 방식으로, parent의 outside represention과 sibiling의 inside representation, 그리고 그들과의 결합 확률로부터 다른 cell의 outside representation을 구한다. 기본적으로 inside와 동일한 형태이고, parent와 sibiling의 값 출처가 다르기 때문에 아래 정도의 변형이 있다. Composition function은 inside pass와 파라미터가 공유될 수 있다. Outside chart의 전체 root로는 inside pass에서 구한 문장 전체의 input representation을 사용하는 것이 아니라 별도의 bias를 학습하여 사용한다.
Objective
Leaf의 representation이 원래 input word를 reconstruct하도록 훈련된다. Negative sample N개와의 차이에 대해 CE를 학습한다. (Hinge loss도 실험함)
가장 likelihood가 높은 tree는 inside/outside chart에 들어간 compatibility score $e, f$ 를 사용하여 CYK 알고리즘으로 추출한다.
실험
1. Unsupervised parsing
이 결과 자체는 애매하다.
-
Binarized WSJ (WSJ 테스트셋을 binarize하였음)
PRPN, [ON-LSTM] 대비 F1 높고 average depth 깊음 (5.9, 5.6 vs 8.0)
-
MultiNLI (CoreNLP supervised parser로 구한 automatic parse tree가 gold로 사용됨)
마찬가지로 PRPN 대비 좋지만, supervised parser 결과 replicate했다는 의미 정도.
-
WSJ-10, WSJ-40
WSJ-10의 경우 non-neural parser들이나 PRPN보다 성능 떨어짐
2. Unsupervised phrase segmentation
Span의 maximum recall로 채점. 언어학에서의 syntactic tree를 만드는 데는 이 기준이 중요할 것 같다.
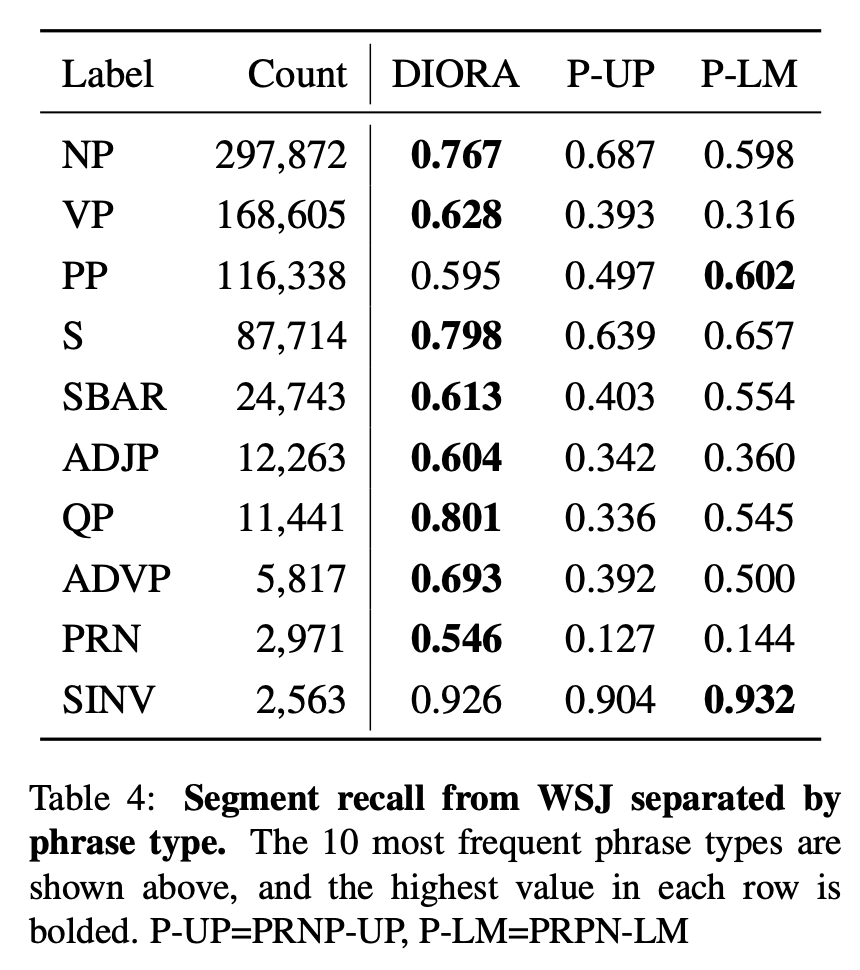
3. Phrase similarity
Query span의 phrase representation (concatenated inside-outside) $[\bar{a}; \bar{b}]$ 를 구한다. 그리고 다른 span들과의 cosine similarity를 구하여 얻은 K-most similar span들과의 레이블 일치 여부로 채점한다.
-
CoNLL 2000 (NP, VP… 등 span 포함)
ELMo에 비해 K=1, 10, 100에서 모두 나았다.
-
CoNLL 2012 (NER)
ELMo보다 모두 못했다. NER는 structure보단 content에 heavily dependent해서 그럴수도?
4. Qualitative analysis
GT와 다른 방향으로 계속 branching 하는 경우가 있음. V와 particle을 자주 묶는 경향이 있음.
Leave a comment