
Neural Language Modeling by Jointly Learning Syntax and Lexicon (PRPN)
이 논문은 LSTM state간의 skip-connection으로 constituent간의 dependency를 표현한다. CNN을 사용하여 인접한 두 단어 노드간의 syntactic distance를 계산하고, 그에 기반해 이전의 노드들이 현재 노드가 속한 constituency의 boundary 노드일 확률을 unsupervised 방식으로 예측한다.
Dependency range를 표현하는 soft gate variable로 modulate한 structured attention을 이전의 모든 토큰들에 대해 적용함으로써, constituency 관계를 반영하여 다음 단어를 예측하는 LM 과제를 수행한다.
모델
Parsing Network
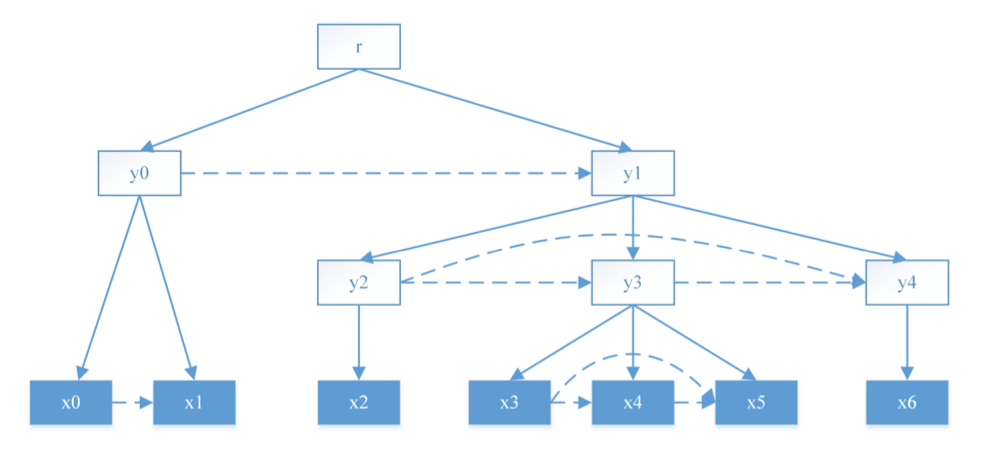 Target tree 구조.
Target tree 구조.
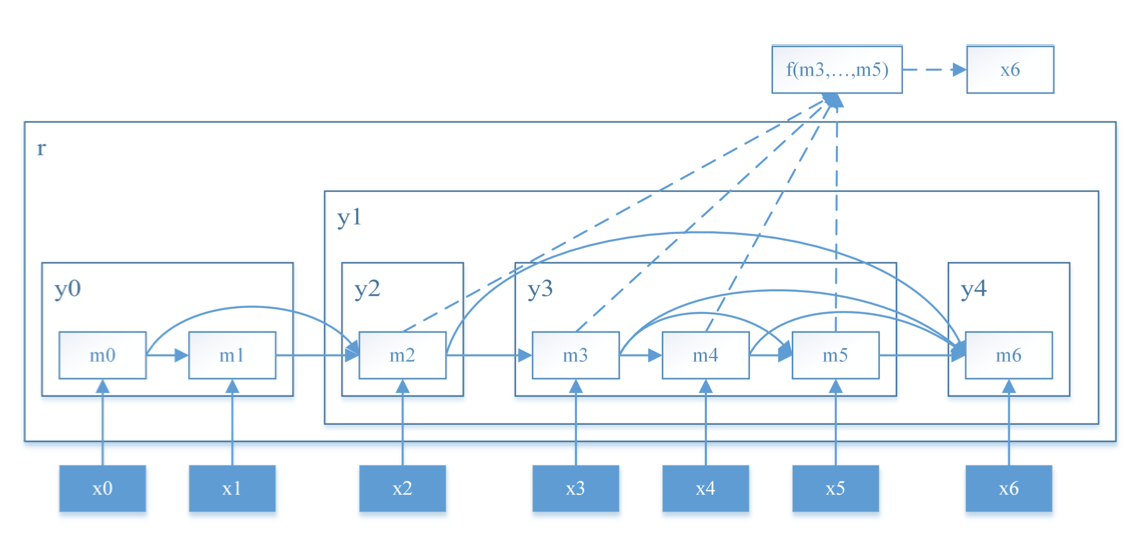 모델이 표현하는 구조.
모델이 표현하는 구조.
Tree structure는 constituent들간의 부모-자식 또는 sibling 관계로 구성된다. 이 관계는 leaf 노드간의 dependency로 표현한다. 한 constituent에 걸리는 모든 관계는 해당 constituent의 가장 왼쪽 자손 노드, 즉 왼쪽 boundary node에 걸린다 (예: $y_1, y_2$ 에 걸리는 관계는 $m_2$ 에 표현됨). 관계가 있는 두 constituent (예: $y_3, y_4$) 에 대해서, dependency 담당 노드 (제일 왼쪽 자식 $m_3, m_6$)간의 skip-connection을 만들기 때문에, 두 노드가 sequentially 떨어져 있어도 dependency를 표현할 수 있다.
1. Skip connection host node
각 노드 $x_t$ 에 대해, 자신이 속하는 constituent의 dependency 담당 노드, 즉 (skip) connection이 걸릴 호스트 노드인 $l_t$ 의 인덱스를 찾아야 한다. $l_t$ 는 무조건 $x_t$ 보다 왼쪽에 있게 된다.
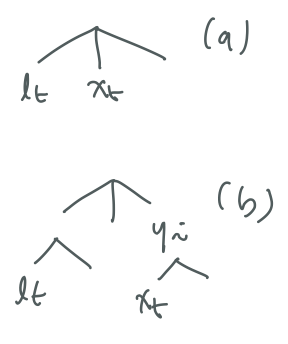 가능한 두 가지 상황.
가능한 두 가지 상황.
그런데 $l_t$ 는 unobserved latent variable이므로, 실제로는 아래처럼 근사를 한다.
여기서 $\alpha_j^t$ 는 $l_t \neq j$ 일 확률 (roughly, $x_t$ 와 $x_j$ 가 같은 constituent에 속할 확률)로서, syntactic distance $d$ 를 사용해 정의된다.
Constituent를 시작하는 노드에는 1에 가깝게 큰 $1-\alpha_i^t$ 가 걸려야 하고, 나머지 노드에는 0에 가까운 값이 걸려야 한다.
$\tau$ 가 +inf 이면 hardtanh이 sign이 되어서 partial overlap이 없는 valid tree가 보장된다.
2. Syntactic distance
$d_j$ 를 sequentially adjacent한 두 단어 $(x_{j-1}, x_j)$ 사이에 성립하는 syntactic relation의 거리라고 할 때, 파싱의 목표는 $d_j$ 가 크면서 $x_t$ 에 가장 가까운 단어 $x_j$ 를 찾는 것이다. $d_j$ 가 크다는 것은 $x_{j-1}$ 과 $x_j$ 가 같은 subtree에 속하지 않는다는 것, 즉 두 단어가 constituent의 boundary라는 의미이기 때문이다. 반대로 sibiling인 두 노드간의 syntactic distance는 0에 가까워야 한다.
$d_i$ 는 $x_{i-L}, \dots, x_i$ 에 대해 2-layer convolution을 적용하여 예측한다.
3. Soft dependency gate
Skip-connection을 control하는 gate $g_i^t = 1\;(l_t \leq i < t)$ 로 정의된다. $l_t$ 부터 $t$ 까지 열려있기 때문에, $x_i$ 가 $x_t$ 와 동일한 constituent에 속한다는 dependency range를 표현한다. 실제로는 binary value 대신 expectation을 사용하므로 soft gate이다.
Reading & Predict Network
Reading network는 과거 노드들 중 $t$ 와 내용적으로 (through content-based attention), 그리고 구조적으로 (through gate modulation) 관계있는 것들을 반영하여 LSTM state $m_t = (h_t, c_t)$ 를 업데이트한다.
$t$ 이전의 모든 토큰들에 대해, 일단 scaled dot-product으로 content-based attention $\tilde s_i^t$ 를 구한다. 그 후, parsing network가 구한 soft gate로 modulate한 structured attention weight를 구한다. 예측된 gate 값이 높아야 높은 weight가 assign된다.
$m_t$ 는 previous 토큰들의 $m_i$ 의 weighted sum인 summary vector를 사용하여 업데이트한다.
Predict network도 동일한 방식의 structured attention을 사용한다. $\tilde h_{l_{t+1}\,:\,t-1}$ 와 $\tilde h_t$ 를 계산하고, 이를 인풋으로 하여 다음 토큰의 확률을 예측한다.
트리 복원하기
Syntactic distance를 decreasing order로 sort한다. 가장 큰 $d_i$ 를 갖는 노드 $i$ 를 기준으로, 양 옆으로 constituent $(x_{<i}), (x_i, (x_{>i}))$ 로 분리한다. 이 과정을 두 constituent에 대해서 다시 시행한다.
실험
1. Char-level LM
- Penn Treebank; BPC로 평가
2. Word-level LM
- Penn Treebank, Text8; Perplexity로 평가
- Ablation results. “-Parsing Net”은 parsing network와 structured attention을 일반 content-based attention으로 바꾼 모델로, 논문에서 사용한 구조가 LM에 도움이 됨을 알 수 있다.

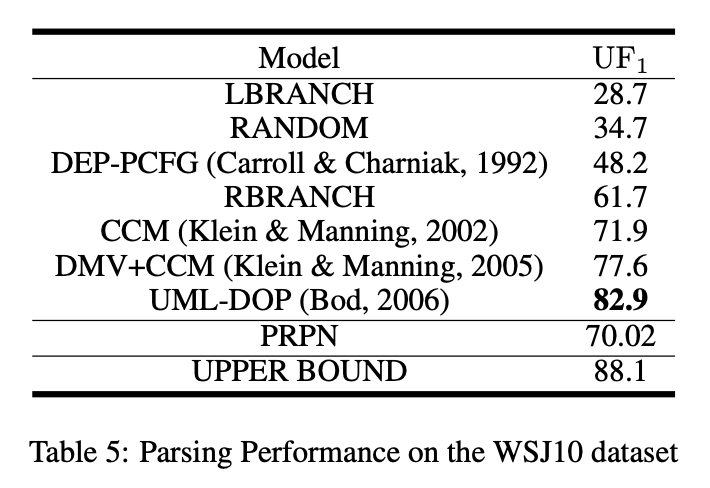
3. Unsupervised constituency parsing
- WSJ10 : Penn Treebank에서 추출, len 10 이하, 7.4K
- 예측된 constituency span이 treebank parse에 있는가로 F1을 계산한다. Trivial한 constituent (length 1 or 전체 문장)는 계산에서 제외한다.
Leave a comment