
Structured Alignment Networks for Matching Sentences
의미의 합성성에 주목하여 latent subtree들의 비교를 통해 두 문장의 의미 관계를 파악하고자 한다. 각 문장의 트리를 구한 후 문장 단위에서 비교하는 것이 아니라, 두 문장을 span 단위에서 비교함으로써 트리를 만들어간다 (CYK 차트를 채워간다)는 점이 특징이다.
각 문장의 벡터는 1) 한 문장의 모든 가능한 span을 다른 문장의 모든 가능한 span과 비교한 structured attention과, 2) inside-outside로 구한 각 span이 constituent로 나타날 확률을 바탕으로 계산된다.
배경 지식
Inside-outside algorithm
Binary latent variable $c_{ikj} \in {0,1}$ 이 i~j에 걸쳐 있으면서 k가 left, right의 분할 지점인 subtree의 존재 여부를 나타낸다고 하자. Binary tree의 경우 inside-outside 알고리즘으로 $p(c_{ikj}=1)$ 를 계산할 수 있다.
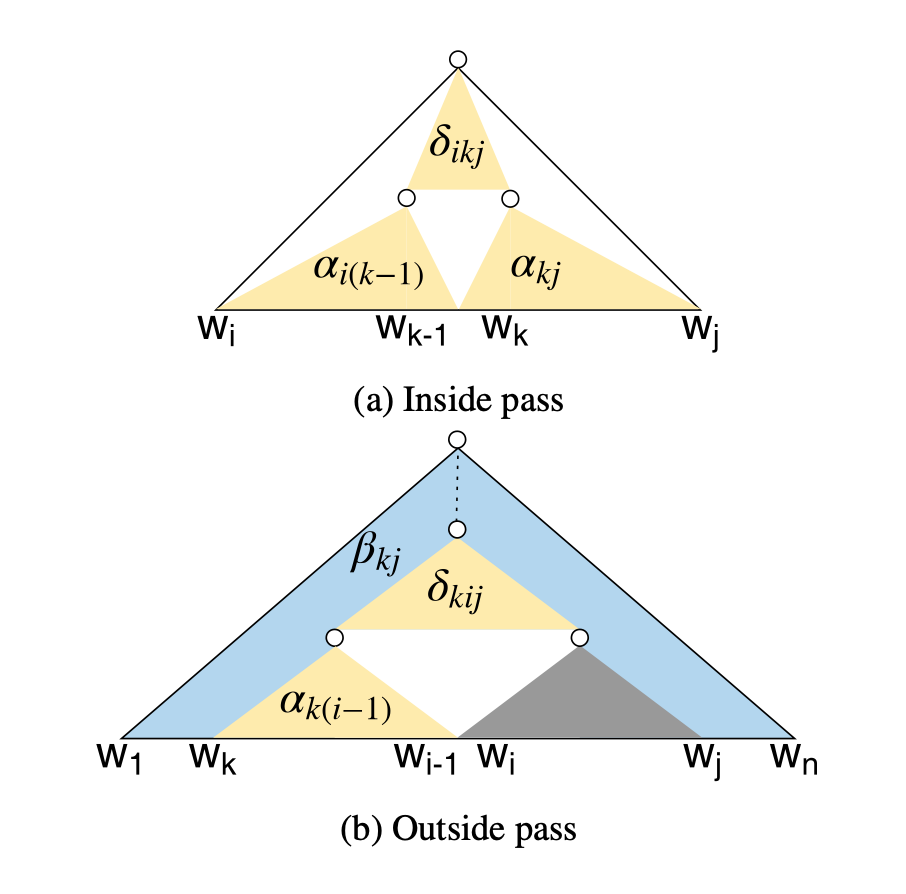
Inside. Bottom-up으로, span [i,j]의 inside score $\alpha_{ij}$ 를 split point k에 대해 marginalize하여 구한다.
Outside. Top-down으로, span [i,j]가 right child일 경우와 left child일 경우로 나누어 생각할 수 있다.
Constituent probability. 각 span의 normalized marginal probability. 가능한 모든 parse에 대해 marginalize되어 있다.
Tree probability. 문장 $x$ 에 대한 트리 $z$ 의 확률은 해당 트리를 구성하는 constituent들의 확률의 normalized product로 나타낼 수 있다.
모델
For CYK chart
span [i,k]의 representation은 [i, k] 사이의 biLSTM hidden의 maxpool과, $h_k - h_{i-1}$ (forward pass), $h_i - h_{k+1}$ (backward pass) 를 concat하여 사용한다. 두 child span [i,k] 와 [k,j]의 representation을 bilinear에 통과시켜 inside-outside의 $\delta_{ikj}$ 로 사용한다.
CYK 차트는 모든 가능한 span의 노드를 포함하고, 각 span이 constituent일 marginal probability $\rho_{ij}$ 를 저장한다.
Structured alignment 학습하기
두 문장간의 가능한 모든 span 쌍에 대해서 structured attention score를 계산한다. $sp_{ij}^a$ 가 문장 a의 span [i,j]의 representation일 때, 문장 b의 span들에 대한 attention vector는 다음과 같다. ($A_{kl}$ 도 마찬가지 방식으로 구함)
Alignment를 반영한 span vector들을 구한 후, 이들에 대한 weighted sum으로 sentence vector를 구한다. Inside-outside로 얻은 marginal probability $\rho_{ij}$ 가 weight로 사용된다.
Objective.
End-to-end. Downstream task (QA, NLI) 의 결과를 사용한다.
두 문장간의 관계를 파악해야 하는 downstream task에 최적화된 방식으로 트리가 학습되므로, 범용적인 constituency parse tree로 쓰기는 어렵다.
실험
NOTE. Not very enlightening…
1. QA (Answer sentence selection)
-
Truncated TREC-QA; MAP, MRR(mean reciprocal rank)로 채점
Structure를 반영하지 않은 attention baseline들보다 성능이 약간.. 낫다.
- Word-level decomposable attention Parikh et al., 2016: structured attention 대신 일반적인 attention을 사용하고, marginal constituent score로 re-normalize하는 과정을 뺌
- Simple span alignment: biLSTM에서 얻은 span representation을 MLP와 softmax를 통과시켜 shallow span distribution을 구함
기존의 모델들 Rao et al., 2016, Wang et al., 2017 보단 성능이 낮다.
2. NLI
-
SNLI
동일 baseline보다 accuracy가 약간.. 높다.
기존의 모델들 Chen et al., 2016, Gong et al., 2017 보단 성능이 낮다.
3. Qualitative analysis
- Visualization of CYK chart for a sentence pair.
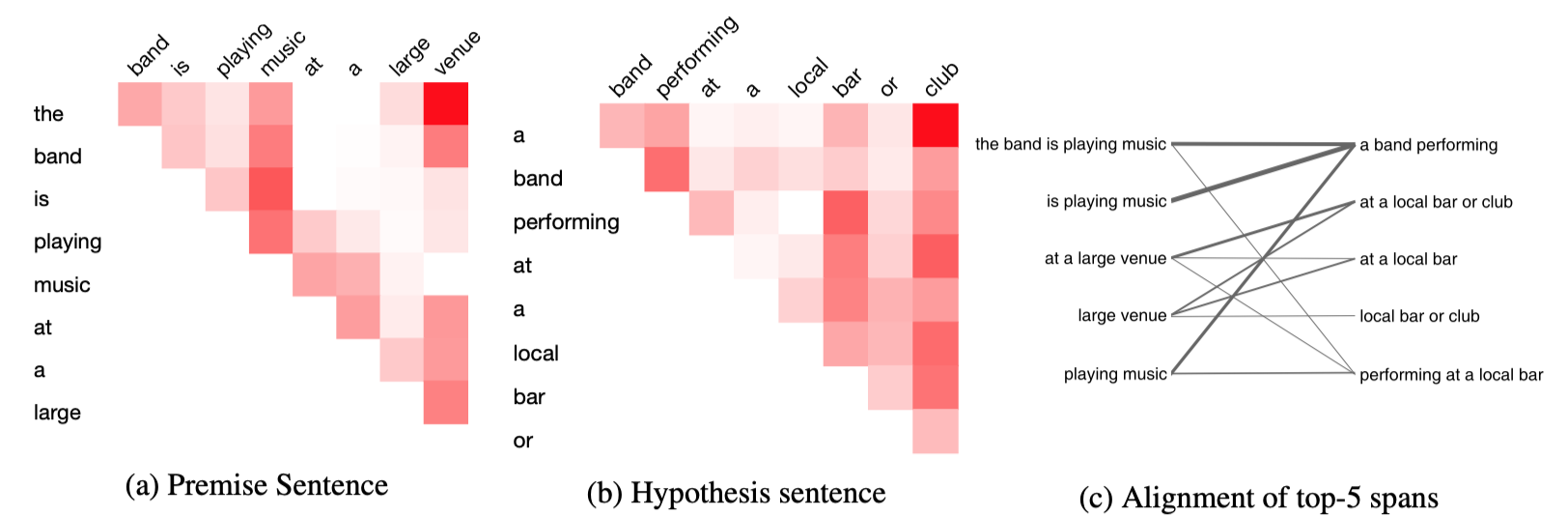
- 범용적인 parse와의 비교. CoreNLP로 얻은 parse의 constituent를 bracket으로 변환하고, 이 모델에서 CYK로 얻은 most likely parse가 gold bracket을 얼마나 찾는지 accuracy를 본다. Left-branching, right-branching보단 낫지만 10%대에 머문다.
Additional to-read
- 두 문장의 structure 비교 (non-differentiable)
- Task-specific tree
Leave a comment