
A Multi-Task Approach for Disentangling Syntax and Semantics in Sentence Representations (VGVAE)
문장 representation에서 의미 LV와 통사 LV를 구분하여 사용하는 VAE를 제안하였다. 또한 의미에 걸리는 paraphrase discrimination loss, 통사에 걸리는 word position loss, 그리고 둘 다에 걸리는 paraphrase reconstruction loss를 고안하여 objective에 추가하였다.
이들 loss를 사용했을 때 semantic variable과 syntactic variable이 각각 의미적/통사적 유사도 평가 과제에서 보이는 성능 gap이 커져서, 둘이 서로 다른 정보를 인코딩한다는 것을 확인하였다.
통사/의미 요소의 구분은 generation control에 사용될 수 있다.
모델
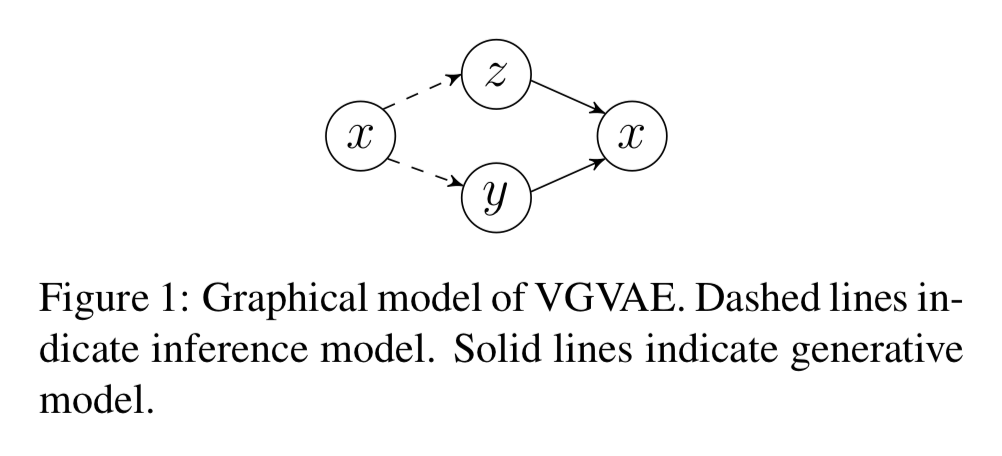
Semantics에 해당하는 LV y와 syntax에 해당하는 LV z를 구분하고, 둘을 상호독립으로 놓아 LV에 대한 posterior $q_\phi(y,z|x) = q_\phi(y|x)q_\phi(z|x)$ 로 표현한다.
Inference net은 word averaging encoder이고, 여기에 FFN을 붙여 distribution family의 parameter $\mu(x), \sigma(x), \kappa(x)$ 를 내놓는다. Generative model $p_\theta(x|y,z)$ 는 BOW output을 내놓는 FFN이다.
Syntax의 경우 BOW 모델 대신 biLSTM을 사용할 수도 있다 (inference, generative 모두). 이렇게 하면 특히 문장이 길어질수록 constituency parsing과 POS tagging 성능이 꽤 향상된다.
Semantic encoder와 syntactic encoder는 서로 다른 word embedding space를 사용하도록 하였다.
Distribution families for LVs
vMF for semantics. 두 문장간의 유사도를 모델링하는 데 사용되어 온 분포로, 여기서는 semantics variable y를 이 분포로 나타낸다. Posterior $q_\phi(y|x) = vMF(\mu_\alpha(x), \kappa_\alpha(x))$, prior $p_\theta(y) = vMF(\cdot,0)$
Gaussian for syntax. Posterior $q_\phi(z|x) = \mathcal{N}(\mu_\beta(x), \mathrm{diag}(\sigma_\beta(x)))$, prior $p_\theta(z) = \mathcal{N}(0, I_d)$
Multi-Task Objective
Basic VAE objective. Inference net에서 샘플링된 LV에 조건부인 conditional likelihood를 최대화하고, 각 LV에 대한 inference posterior와 prior 사이의 KL divergence는 최소화한다.
Paraphrase reconstruction loss. Paraphrase 관계인 두 문장 x1, x2에 대하여, y끼리는 swap하고 z는 유지했을 때도 reconstruct이 잘 되도록 한다.
Discriminative paraphase loss (for semantics). Paraphrase 관계인 문장과의 cosine similarity가 negative sample과의 유사도보다 높도록 한다. 문장간 유사도는 vMF mean direction $\mu_\alpha$ 끼리 측정한다. Negative sample은 target 문장과의 cosine similarity에 argmax를 걸어 찾는다. 학습 초기에는 negative sample이 좋지 않아서 DPL이 불안정하므로, 1에폭 이후부터 추가한다.
Word position loss (for syntax). z와 함께 특정 position에 있는 word embedding을 받아 해당 position을 복구해 내는 FFN을 사용한다.
실험
Dataset
- Training: ParaNMT-50M 중 500K
- Development: STS-2017
- Semantic similarity evaluation: STS-2012~2016
- Syntactic similarity evaluation: Penn Treebank, ParaNMT-50M 중 5M
Metric
- Semantic variable의 similarity: $\mathrm{cosine}(\mu_\alpha(x_1), \mu_\alpha(x_2))$
- Syntactic variable의 similarity: $\mathrm{cosine}(\mu_\beta(x_1), \mu_\beta(x_2))$
Results
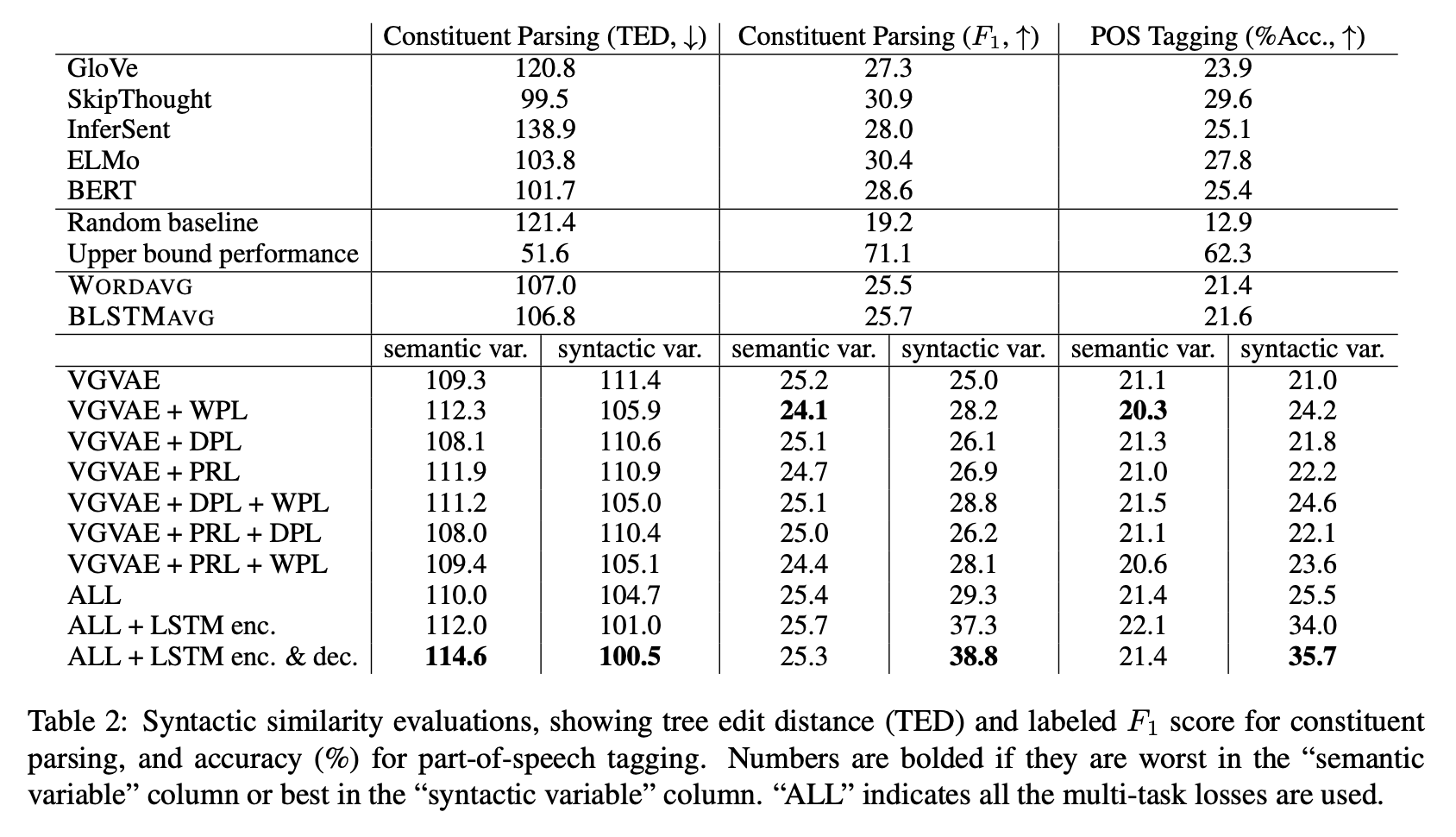
Semantic similarity. STS 테스트 셋에 평가한 결과, base VAE loss만 있을 때는 y와 z의 metric이 별 차이를 보이지 않았지만 3가지 loss 중 하나라도 추가했을 때는 둘의 성능이 달라졌다 (y는 증가, z는 감소). 둘의 차이는 loss를 추가할수록 대체로 벌어진다.
Syntactic similarity. Gold parse와의 TED, F1, 그리고 POS tagging을 확인하였다. 생성된 문장의 parse tree로는, syntactic variable의 cosine similarity에 기반해서 nearest neighbor를 트레이닝 셋에서 찾아 그 문장의 parse tree를 대신 사용하였다. 여기서도 마찬가지로 y와 z의 metric이 차이를 보인다. Syntactic variable과는 무관한 DPL의 사용도 syntactic variable의 성능을 향상시킨다. 논문에서는 DPL로 인해 semantic variable이 paraphrase로부터 얻을 수 있는 의미적 정보를 잘 포착하면서, 이로 인해 syntactic variable은 상보적인 통사 정보를 캡쳐하는 것으로 해석하였다.
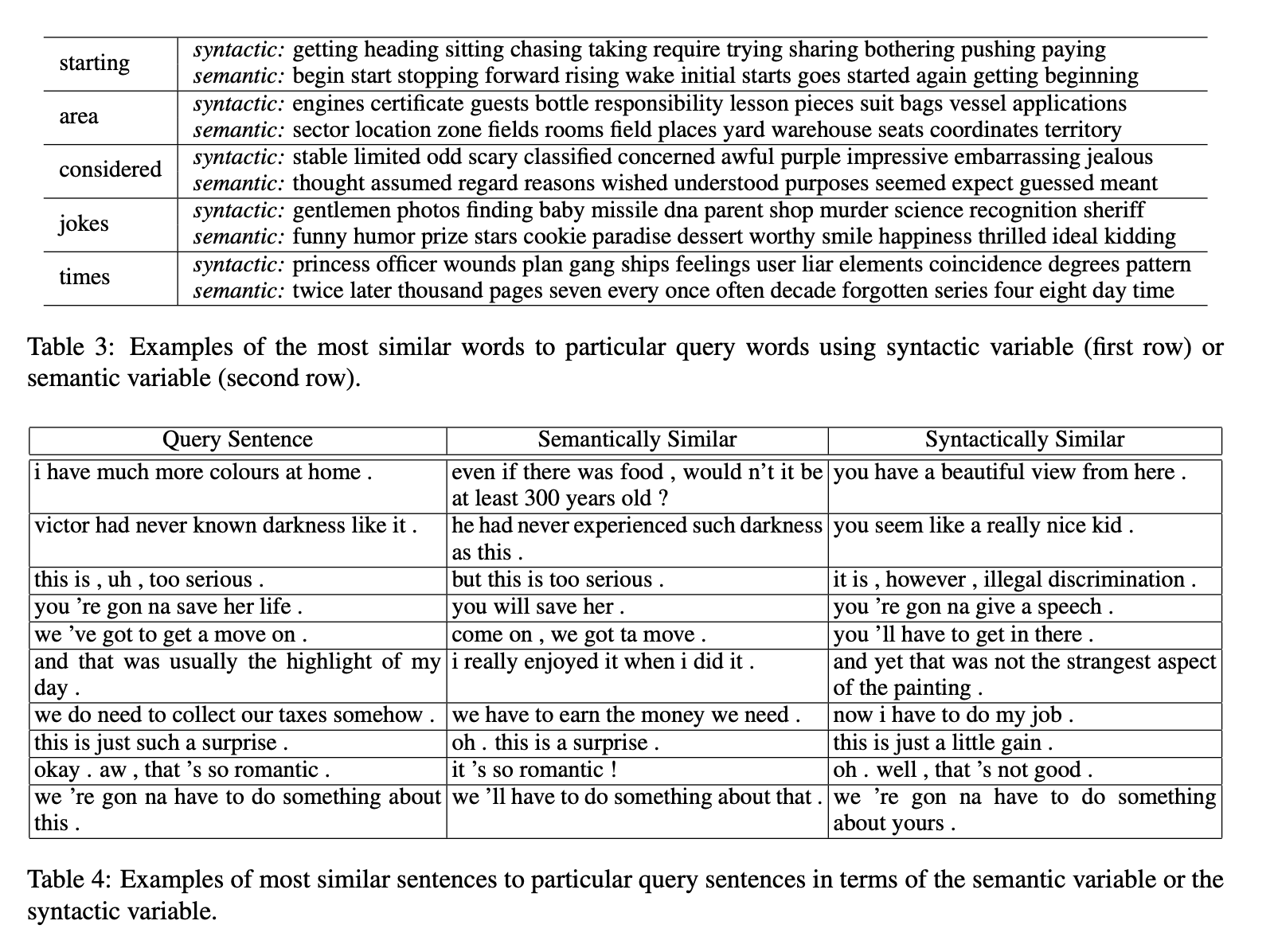
의미적/통사적으로 유사한 단어/문장 찾기. 이러한 게 가능하다.
Leave a comment