
Paraphrase Generation with Deep Reinforcement Learning
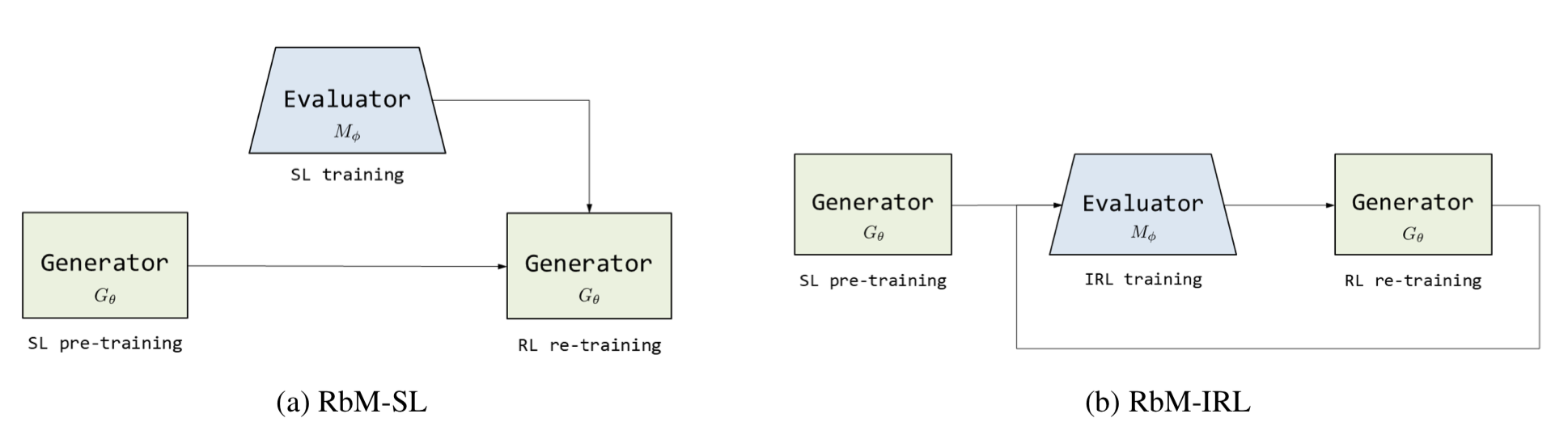
Evaluator가 generator의 fine-tuning 단계에서 reward를 제공하도록 한다. Evaluator는 positive/negative sample에 대해 미리 binary classifier로서 훈련된 후 활용될 수도 있고 (suprevised learning), ranking 모델로서 generator와 minmax 식으로 교대로 훈련될 수도 있다 (IRL).
배경 지식
Decomposable attention (Parikh et al., 2016)
NLI를 두 문장을 align하는 문제라고 할 때, 복잡한 문장 $\mathbf{\bar{a}}$ 가 문장 pair에 포함되어 있다고 하자. 이 때 $\mathbf{\bar{a}}$ 전체에 대한 representation을 만드는 대신, $\mathbf{\bar{a}}$ 의 subphrase와 상대 문장을 align하는 상대적으로 쉬운 문제 여러 개로 쪼개어 (“decompose”) 병렬적으로 풀 수 있도록 한다. 다음의 3단계로 구성된다.
Attend. Complexity가 낮은 decomposition. Normalized attention $\beta_i$ 는 $\mathbf{\bar{b}}$ 의 subphrase 중 $\alpha_i$ 와 (soft) align된 것을 나타낸다.
Compare. 이제 모든 i와 모든 j에 대해서 aligned phrase를 얻었으므로, comparison vector를 각각 (독립적으로) 만든다.
Aggregate. Summed comparison vector $\mathbf{v}_1$ 와 $\mathbf{v}_2$ 를 계산하고, 이들을 classifier에 통과시켜 최종 분류 결과를 얻는다.
모델
Evaluator learning
Decomposable-attention model을 evaluator로 사용한다. 두 문장 X, Y의 의미적 유사도를 계산하며, 이 점수는 generator를 RL로 fine-tune할 때 reward로 사용된다. 두 가지 방식으로 학습할 수 있다.
1. Supervised learning
Positive, negative sample이 모두 있을 때 쓸 수 있다. pos/neg를 구분하는 binary classifier로서 evaluator $M_\phi$ 를 학습한다. X를 paraphrase corpus나 non-parallel corpus에서 샘플링한 후, pointwise CE로 학습한다. Generator가 fine-tuning에 들어가기 전 이미 학습을 완료해야 한다.
2. Inverse reinforcement learning
IRL이란 expert demonstration으로부터 reward 함수를 배우려는 작업이다. IRL로 찾은 reward $R^*$가 정말 optimal하다면 gold paraphrase (=expert demonstration)가 받는 리워드가 어떠한 policy로 만들어진 paraphrase가 받는 리워드보다도 높아야 하고, 정책이 향상될수록 그 갭(“margin”)이 작아져야 한다. Evaluator는 supervised learning에서와 달리 binary classifier가 아니라, 더 좋은 paraphrase에 더 큰 reward를 부여하는 ranking 모델이다 (cf. RankGAN, for text generation).
Generator의 pretrain을 마친 후, evaluator와 generator를 교대로 update한다. Minmax learning으로, generator는 margin이 작은 $\hat{Y}$ 를 생성해서 evaluator로부터 나오는 expected cumulative reward를 높여야 하고, evaluator는 reward를 낮추어야 한다.
Generator learning
Pointer-generator 등 seq2seq 계열 generator를 사용한다. Parallel data에 대해 MLE로 pretrain한다. 이후 RL로 fine-tune하는데 이 때 evaluator가 주는 reward를 사용하며, fine-tune 단계에서는 parallel data가 필요하지 않다. Paraphrase corpus나 non-parallel corpus에서 샘플링한 $X$ 에 대해서 $\hat{Y}$ 를 generate한다 (t=T용 reward를 여기에 대해 계산). 이후 t=1…T까지 reward shaping을 하면서 gradient를 accumulate한다.
PG 식:
따라서 gradient accumulation은 다음과 같다.
유용한 훈련 기술들
Reward shaping (as in Yu et al., 2017)
t=T에만 발생하는 sparse reward를 쓰면 좋지 않으므로 intermediate cumulative reward를 사용한다. 현재 position $t$ 까지 generate된 시퀀스는 given으로 받고, 다음 position $t +1$ 부터 끝까지의 시퀀스 N개를 MC sampling한 후 완성된 시퀀스에 대해 evaluator를 돌린다. N개의 샘플에 대한 평균을 내어position $t$ 에서의 intermediate reward로 사용한다.
Reward rescaling
IRL을 쓰는 경우 evaluator가 계속 업데이트되므로, reward의 단순 moving average는 baseline으로 쓰기에 불안정하다. Generator는 여러 (D개) paraphrase를 생성하고 evaluator가 각각의 랭킹을 계산하므로, 랭킹에 근거하여 평균과 분산을 control하여 PG를 더 안정적으로 할 수 있도록 한다. rank(d)는 d번째 paraphrase의 랭킹, rank(t)는 reward shaping을 적용했을 때 각 타임스텝 t에서 d번째 paraphrase의 랭킹이라고 할 때, 다음처럼 조정된다.
IRL에만 쓰는 건 아니고, 논문에서는 supervised learning의 경우에도 사용하였다.
Curriculum learning
각 example에 diffulculty weight $w^k$ 를 부과하여 새로운 evaluator objective를 사용한다.
Input X와 output Y 사이의 edit distance로 모든 input 샘플들의 랭킹을 매기고, reward scaling에서와 유사하게 랭킹을 구한다.
$\delta$ 값을 처음에는 크게 했다가 나중에 줄이면, 처음에는 랭킹이 낮은 (=쉬운) 샘플들이 주로 뽑히고 나중에는 모든 샘플의 추출 확률이 0.5로 수렴한다.
실험
Datasets
- Quora question pair dataset
- Twitter URL paraphrasing corpus
- Positive, negative example이 모두 있기 때문에 supervised learning과 IRL 모두에 적용 가능.
Results
- Vanilla / ROUGE-RL pointer-generator 대비 성능이 높았다.
- Dataset에 따라 SL이 좋은 경우도, IRL이 좋은 경우도. (Human eval도 마찬가지)
Leave a comment