
Unsupervised Recurrent Neural Network Grammars
이 논문은 amortized variational inference를 사용하여 latent tree space에 대해 marginalize하는 문제를 해소하고 RNNG를 비지도 학습한다. Generative 모델은 stackLSTM과 treeLSTM으로 구성되며, inference net로는 CRF parser를 사용하였다.
Supervised RNNG와 LM 성능은 비슷하지만 파싱 성능은 떨어진다. 하지만 다른 unsupervised grammar induction 모델들과는 파싱 성능이 비슷하다.
배경 지식
RNNG (Dyer et al., 2016)
Top-down transition-based supervised parsing으로, 스택과 버퍼를 사용하여 n-ary 트리를 순차적으로 만들어나간다. RNN을 사용하여 transition sequence를 선택하므로, (PCFG 등의) context-free 모델에서 하는 independence 가정은 유지되지 않는다. Gold transition은 gold 트리를 depth-first, left-to-right traversal하여 얻는다.
제한된 알파벳의 terminal symbol만 포함하는 버퍼와 action history의 representation은 RNN으로 얻고, 스택의 representation은 stack LSTM을 사용하여 얻는다. 현재 상태의 임베딩 $\mathbf{u}_t$은 이 세 가지를 concat하고 linear를 통과시켜 얻는다. 매 타임스텝마다 $\mathbf{u}_t$ 에 근거하여 classifier가 정해진 액션 셋 중 한 가지 액션을 고른다.
두 가지 버전이 있는데, 희한하게도 generative 모델의 파싱 성능이 더 좋다.
1) Discriminative model.
- NT(XP): Open nonterminal symbol XP를 스택에 푸쉬
- SHIFT: Terminal symbol x를 버퍼에서 꺼내서 스택에 푸쉬
- REDUCE: Open nonterminal이 나올 때까지 스택 팝하고, biLSTM을 사용하여 이들을 child로 갖는 constituent의 representation을 만든다 (따라서 n-ary tree가 됨). 새로운 constituent의 label로는 스택에 있는 open nonterminal이 사용된다. Nonterminal을 완성하는 작업에 해당된다.
2) Generative model. 인풋 버퍼를 두는 대신 terminal symbol을 generate하는 버전이다.
- NT(XP)
- GEN(x): GEN을 하기로 했으면, terminal symbol x를 generate하고 스택과 아웃풋 버퍼에 푸쉬. Class-factored softmax를 사용하여 복잡도를 줄인다.
- REDUCE
Objective. Generative objective는 word sequence $\mathbf{x}$, tree $\mathbf{z}$ 의 joint distribution을 maximize하는 것이다.
Intractable (direct) marginalization. Generative 모델의 LM 성능을 평가하려면 marginal probability $p(\mathbf{x})$ 를 알아야 하고, 파싱을 평가하려면 $p(\mathbf{x,z})$ 를 최대화하는 MAP 트리를 찾아야 한다. 그러나 한 액션은 그 이전의 모든 액션에 대해 dependent하므로, 가능한 모든 트리에 대해서 marginalize하는 작업은 intractable하다. 따라서 discriminative 모델을 이용하여 importance sampling을 시행한다.
모델
NOTE. Dyer et al. (2016)의 오리지널 RNNG는 본래 n-ary tree를 만들 수 있으나, 이 논문에서는 binary tree로 제한하여 2T-1 짜리 shift/reduce action 벡터를 만든다. 또한 constituent label (XP)을 사용하지 않으므로 좀 더 간단한 문제라고 할 수 있겠다.
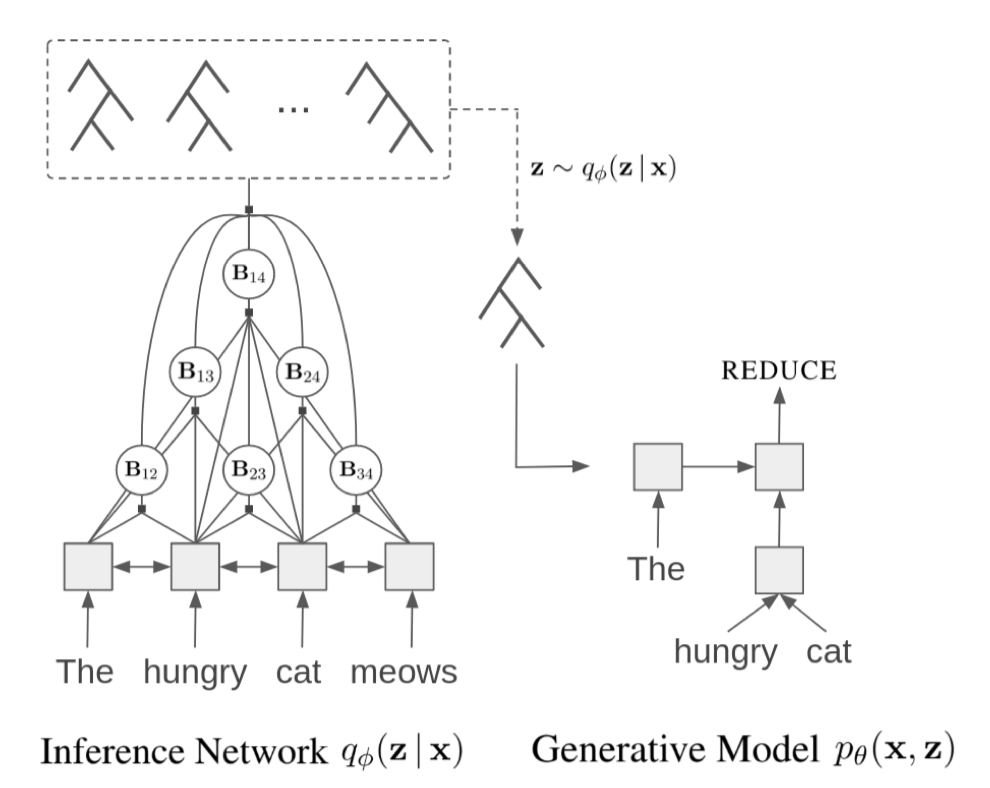
Actions (Generative model)
스택 탑 $(\mathbf{h}{\mathrm{prev}}, \mathbf{g}{\mathrm{prev}})$ 에 근거하여 액션을 결정한다.
Nonterminal을 labeling하지 않으므로, NT(XP)를 제외하고 SHIFT, REDUCE 중에서 선택하면 된다. $p_t = \sigma(\mathbf{w}^T \mathbf{h}_{\mathrm{prev}} + b)$ 에 대한 베르누이 분포에서 샘플링한다.
1) SHIFT. Terminal symbol을 샘플링한 후 stackLSTM을 거쳐 구한 $(\mathbf{h}_\mathrm{next}, \mathbf{e}_x)$ 를 스택에 넣는다.
2) REDUCE. 스택에서 두 개를 팝한다. 이들을 left, right child로 갖는 constituent를 treeLSTM으로 만든 후 $(\mathbf{h}\mathrm{new}, \mathbf{g}\mathrm{new})$ 를 푸쉬하여 스택을 업데이트한다.
Amortized VI
Unsupervised 세팅에서는 가능한 모든 트리에 대해 marginalize한 $\log p(\mathbf{x})$ 를 최대화해야 한다. 하지만 위에서 설명하였듯이 액션간 dependency 때문에 marginalization이 intractable하므로, 다른 방법을 찾아야 한다.
이 논문은 true posterior를 근사하는 variational posterior를 사용하여 log marginal likelihood의 evidence lower bound (ELBO) 를 최대화하는 amortized VI 기법을 사용하여 앞의 문제를 해결한다. ELBO는 generative network $\theta$ 와 inference network $\phi$ 둘 다에 대해 최대화된다.
다시금, variational posterior로부터 importance sampling을 사용하여 ELBO의 gradient를 tractable하게 근사할 수 있다.
Variational posterior에서 트리 $\mathbf{z}$ (shift/reduce action sequence로 바꿔야 함)를 샘플링하고, 이에 기반해 word sequence와 트리의 joint log likelihood를 optimize하여 ELBO를 높인다.

Joint log likelihood 계산. Terminal symbol과 action의 log likelihood로 나누어 생각할 수 있다.
Tree entropy 계산. Inside로 구할 수 있다.

CRF parser as inference net. 오리지널 RNNG가 transition-based parser를 사용하여 independence 가정을 하지 않은 것과 달리, 여기서는 context-free 모델인 CRF parser를 inference network으로 사용한다 (“inductive bias”). Transition-based parser를 쓰면 left-branching 트리로 degenerate하기 때문이었다고 한다.
Constituent span matrix. Span [i,j] 가 constituent를 이루면 $\mathbf{B}_{ij}=1$ 인 binary span matrix $\mathbf{B}$ 를 사용한다. 이 행렬은 트리와 일대일 맵핑되기 때문에 행렬에 대한 posterior를 계산하면 된다.
Span score $s_{ij}$ 는 position+word 임베딩을 biLSTM-MLP에 통과시켜 얻는다. 가능한 모든 span에 대한 summation을 하는 분모는 inside algorithm으로 구할 수 있다.
실험
Major optimization skills
- To reduce variance in gradient estimator: 샘플들의 평균 joint likelihood를 baseline으로 하여 빼줌
- To avoid posterior collapse: 첫 2에폭에서, action log-likelihood (conditional prior)와 entropy의 weight를 0->1로 올리는 기법을 사용함 (KL-annealing과 같은 효과)
- Importance samples K=1000
- Supervised version as baseline: 이 논문의 inference net 구조를 그대로 (importance sampling을 위해 필요한) discriminative parser로 사용함 (오리지널 RNNG와는 다름)
문제점
- 훈련 시간/메모리 많이 들음 (병목: dynamic computation graph)
- Tuning이 까다로움
- Punctuation에 많이 의존함. Punctuation을 없애면 right-branching baseline을 넘지 못함…. 치명적인데?
1. LM
- Penn Treebank: RNNG 논문에서 쓰인 형태. 한 문장씩을 만들기 때문에, 일반적인 PTB LM 결과와는 단순 비교 불가
- Chinese Penn Treebank
- One billion word corpus (subset): PTB보다 100배 가량 큼 (1M)
- Supervised RNNG과 비슷한 성능. PRPN보다는 조금 나음.
2. Parsing
- 동일 데이터셋
- Variational posterior에서 가장 높은 score 받은 트리를 CKY로 구해서 oracle binarized tree에 대한 F1으로 채점.
- Supervised RNNG보다 성능이 많이 떨어짐
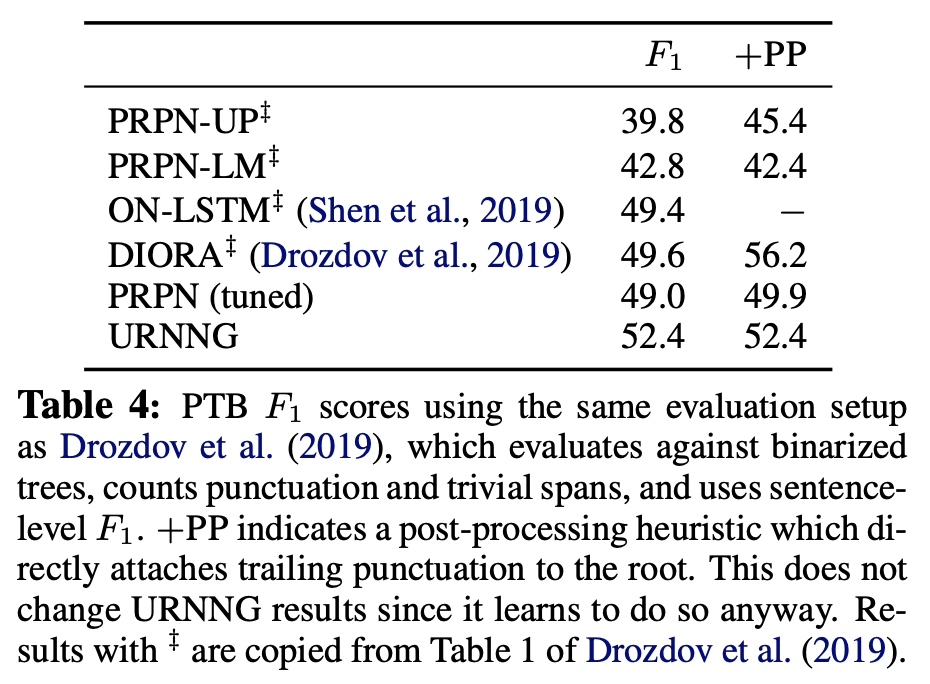
3. Posterior collapse 여부 확인
- Variational posterior와 conditional prior 사이의 KL-divergence가 0이 아님을 확인하였다.
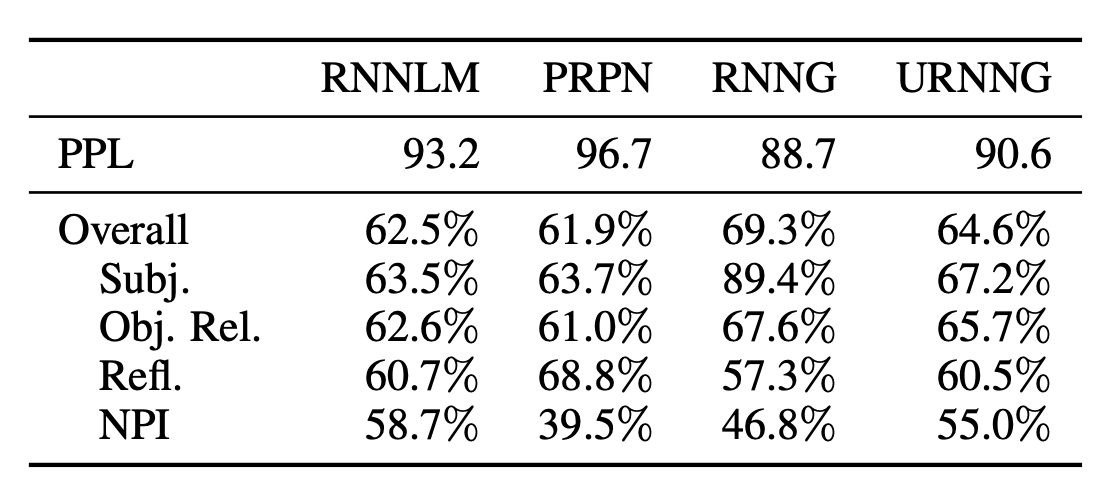
4. Syntactic evaluation (Marvin and Linzen (2018))
- Supervised RNNG보다 못하고, 일반 RNNLM보는 약간 낫다.
Additional to-read
- Independence 가정을 없애면 왜 trivial tree structure가 나타나는 경향이 있는가?
Leave a comment